























PROJECT
Super Cloud Library
KEY POINTS
The Super Cloud Library—a big data analysis and visualization tool for Earth science applications—has been infused into the Data Analytics and Storage System (DASS) at the NASA Center for Climate Simulation and is producing results over twenty times faster than previously deployed manual processes.

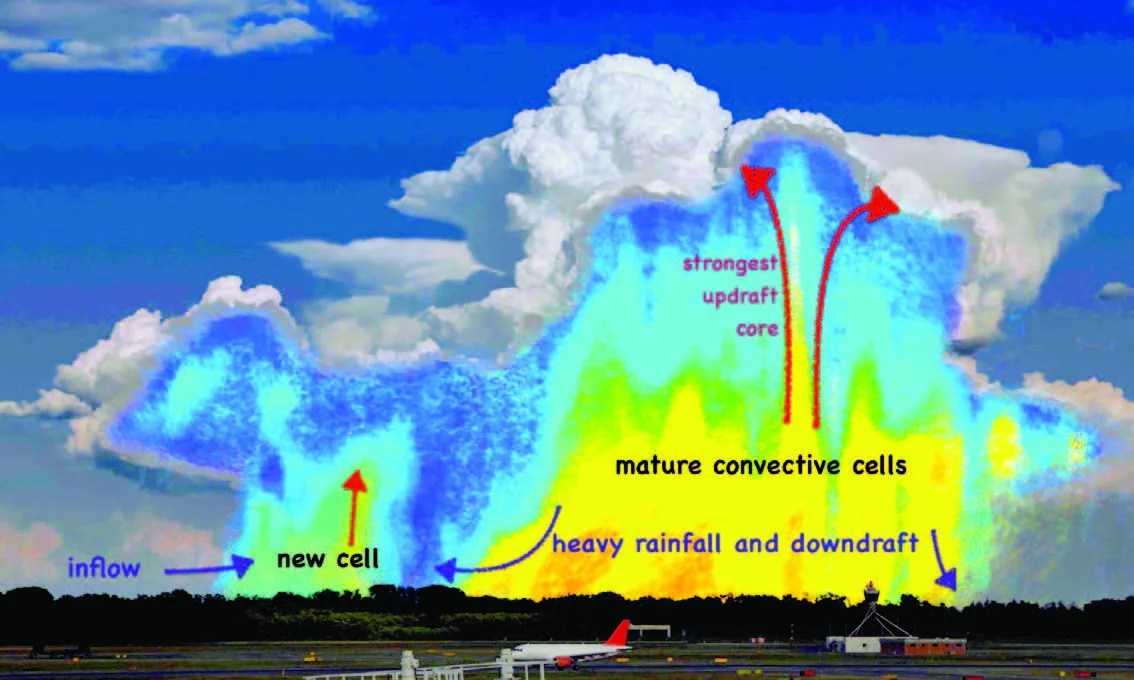
Today’s high-performance computers consisting of hundreds of thousands of processors have enabled ultra-high-resolution, long-term Earth science simulations, such as those used to study cloud formation. The output files of these simulations can be huge—over 150 Terabytes. Not only are such large datasets hard to distribute, they are difficult to analyze with a desktop computer. A NASA team has developed a way for users to obtain adequate insight into these voluminous datasets without downloading them locally.
Researchers at Goddard Space Flight Center (GSFC) have developed the Super Cloud Library (SCL), a big data analysis and visualization tool for use with high-resolution cloud resolving models (CRMs). NASA recently infused the SCL into the Data Analytics and Storage System (DASS) at the NASA Center for Climate Simulation (NCCS) where it has enhanced CRM database management, distribution, visualization, subsetting, and evaluation.
The SCL architecture is built upon a Hadoop framework, which employs the Hadoop Distributed File System (HDFS)—a stable, distributed, scalable, and portable file system. Hadoop enables users to compute and visualize various standard/non-standard statistics. Within the Hadoop framework, a CRM’s diagnostic capabilities are further enhanced with Spark (a big data processing tool), which accelerates the Hadoop MapReduce process by ~100 times.
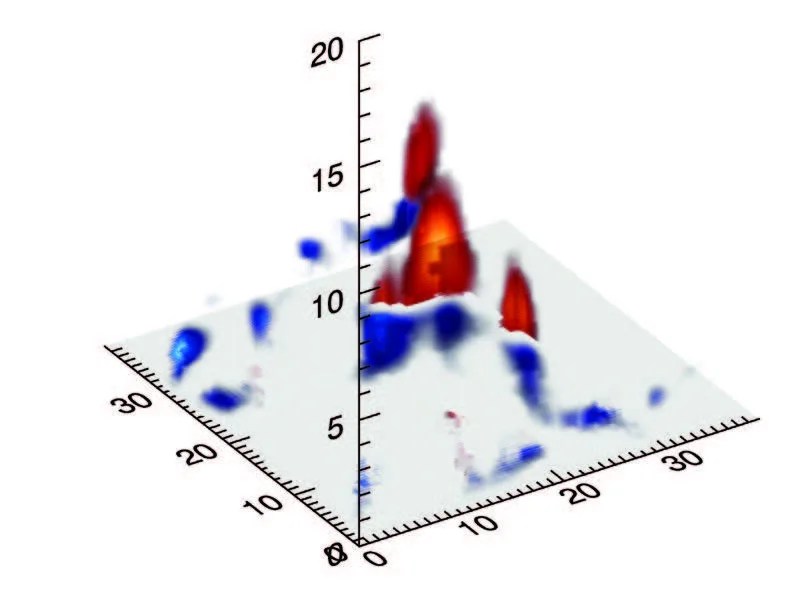
The HDFS data model allows for transforming data from Network Common Data Form (NetCDF) to Comma Separated Values (CSV) format with indexes. Consequently, data can be stored in HDFS and straightforwardly processed by Hadoop-based tools for subsetting and diagnosis. HDFS’s interface definition language (IDL) and Python tool permit users to visualize CRM-simulated cloud properties in two and three dimensions and diagnose HDFS-resident data. Moreover, HDFS’s concurrent Hadoop reader is capable of increasing the speed of reading data from HDFS to be more than 20 times faster than sequential reading. Finally, the HDFS dynamic Hadoop reader can fetch Parallel File System-resident data and make them ready for MapReduce applications including subsetting and diagnosis.
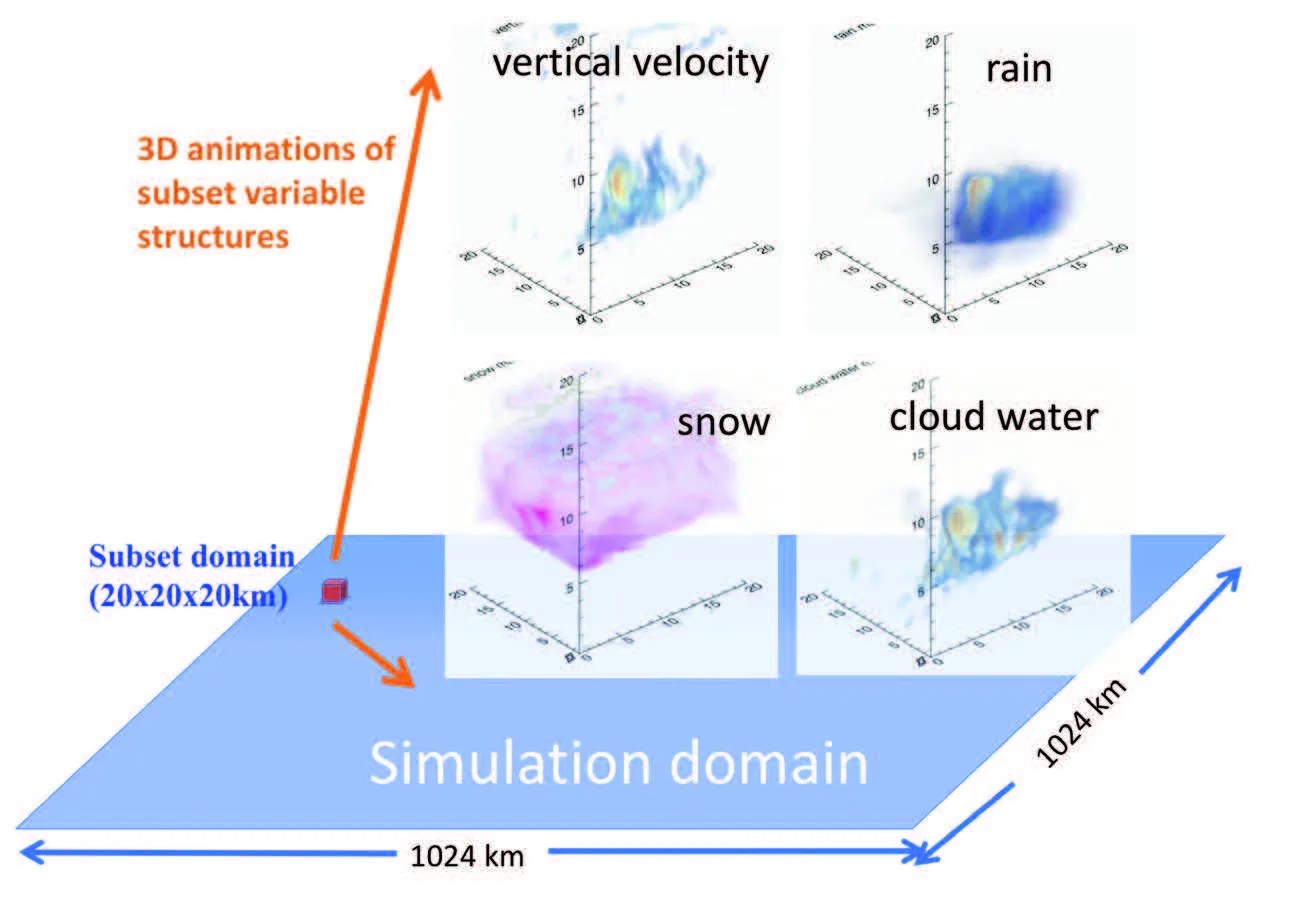
The SCL was built on the NCCS Discover system, which directly stores various CRM simulations, including those produced by the NASA-Unified Weather Research and Forecasting (NU-WRF) model and Goddard Cumulus Ensemble (GCE) model. The team also developed a web portal for SCL to allow a user to subset, diagnose, visualize, save, and download the subset data. SCL allows users to conduct large-scale on-demand tasks automatically, without the need to download voluminous CRM datasets to a local computer. Therefore, the SCL makes CRM output more usable by the science community. SCL’s Technology Readiness Level is level 5 (system prototype in an operational setting). As PI, Dr. Wei-Kuo Tao notes, “The Super Cloud Library implemented within the DASS has enabled climate researchers to analyze extremely large volumes of high-resolution model data without direct access to high-end computing.”
SPONSORING ORGANIZATION
Earth Science Division’s AIST Program
PROJECT LEAD
Dr. Wei-Kuo Tao, NASA GSFC






